
Mercoledì 16 marzo alle 23.11 ho lanciato un twitter mining con gli hashtag #convegnostelline, #stelline16 e #bibliostar (tanto per essere precisi, con la condizione logica “o”, non “e”). Ho terminato lo script venerdì 18 marzo alle 22.37.
I grafici finali di questo lavoro sono:
- Hashtag network
- Betweenness centrality (network dei retweet)
- Eigenvector centrality (network dei retweet)
Per tutto il resto, mi spiego meglio.
Volevo avere la massima quantità possibile di dati grezzi per poter analizzare il network che si sarebbe creato su Twitter nei due giorni di convegno (compreso l’inevitabile follow-up serale di venerdì).
Strumenti utilizzati:
- Python (e la libreria Tweepy) installato su droplet Ubuntu (Digital Ocean). Un bel venv python configurato al minimo, con le sole librerie essenziali allo script.
- Nodejs con MongoDB su droplet parallela (sempre Digital Ocean) per il salvataggio dei dati json e la possibilità di automatizzare l’interrogazione del db e l’esportazione dei campi utili all’analisi (sì, sono molto più a mio agio con i driver per node che non con pymongo, ma è solo una questione di pigrizia immagino).
- OpenRefine
- Excel
- Gephi
- Sigmajs
- Github
Ad oggi tutto questo mi è costato la ridicola somma di $2.50.

Risultato?
1780 tweet raccolti per un totale di 172 account attivi. Numeri un po’ bassi, ammettiamolo, per un live tweeting ma, al di là del dato puramente quantitativo, mi interessava in realtà capire altre cose:
- Chi sarebbero stati gli influencers in un contesto del genere?
- Avrei scoperto una rete a invarianza di scala, e di conseguenza individuato la presenza di hub alla base del famoso effetto “6 gradi di separazione”?
- Come usiamo Twitter durante l’evento più importante del settore (rileggiamoci anche questo post di Virginia Gentilini, tanto per capire di cosa stiamo parlando)?
#stelline16 è stato utilizzato 1218 volte contro le 495 di #convegnostelline.
Magari l’anno prossimo, vista la popolarità del primo hashtag (l’unico, da quel che sembra, ad essere entrato per qualche ora nei TT italiani), usiamo quello e non se ne parla più (non che sia fondamentale, se ragioni con il metodo “non importa che dati mi dai, io raccolgo tutto e poi ottimizzo l’analisi con processi a valle” la questione si risolve velocemente.)
Volendo ci si può anche divertire a considerare popolarità, correlazioni e altro confrontando (seppure un po’ superficialmente) i due hashtag principali del convegno su hashtagify.me:

Uno dei primi dati che sono andato a cercarmi è stato quello sui dispositivi.

Ottenere questo dato è abbastanza facile, se hai deciso di salvare l’intero corpo di ogni singolo tweet, che altro non è che un documento strutturato in questo modo (l’esempio riporta il primo tweet salvato dallo script):
{
“created_at”: “Wed Mar 16 10:11:57 +0000 2016”,
“id”: 710045933292167200,
“id_str”: “710045933292167168”,
“text”: “Domani e venerdì siamo a #stelline16 a parlare di cose belle. Venite allo stand A8 se volete conoscere #MLOLplus https://t.co/pei5VQw8AI =)”,
“source”: “<a href=\”http://twitter.com\” rel=\”nofollow\”>Twitter Web Client</a>”,
“truncated”: false,
“in_reply_to_status_id”: null,
“in_reply_to_status_id_str”: null,
“in_reply_to_user_id”: null,
“in_reply_to_user_id_str”: null,
“in_reply_to_screen_name”: null,
“user”: {
“id”: 4016700033,
“id_str”: “4016700033”,
“name”: “MLOL Plus”,
“screen_name”: “mlolplus”,
“location”: null,
“url”: “https://www.mlolplus.it”,
“description”: “Il prestito degli ebook in abbonamento che sostiene il digitale nelle biblioteche italiane. Da 9,90 euro al mese.”,
“protected”: false,
“verified”: false,
“followers_count”: 242,
“friends_count”: 465,
“listed_count”: 9,
“favourites_count”: 273,
“statuses_count”: 1004,
“created_at”: “Thu Oct 22 12:13:39 +0000 2015”,
“utc_offset”: null,
“time_zone”: null,
“geo_enabled”: false,
“lang”: “it”,
“contributors_enabled”: false,
“is_translator”: false,
“profile_background_color”: “000000”,
“profile_background_image_url”: “http://abs.twimg.com/images/themes/theme1/bg.png”,
“profile_background_image_url_https”: “https://abs.twimg.com/images/themes/theme1/bg.png”,
“profile_background_tile”: false,
“profile_link_color”: “3B94D9”,
“profile_sidebar_border_color”: “000000”,
“profile_sidebar_fill_color”: “000000”,
“profile_text_color”: “000000”,
“profile_use_background_image”: false,
“profile_image_url”: “http://pbs.twimg.com/profile_images/657168450243174400/Dx_tdHdf_normal.png”,
“profile_image_url_https”: “https://pbs.twimg.com/profile_images/657168450243174400/Dx_tdHdf_normal.png”,
“profile_banner_url”: “https://pbs.twimg.com/profile_banners/4016700033/1452155815”,
“default_profile”: false,
“default_profile_image”: false,
“following”: null,
“follow_request_sent”: null,
“notifications”: null
},
“geo”: null,
“coordinates”: null,
“place”: null,
“contributors”: null,
“is_quote_status”: false,
“retweet_count”: 0,
“favorite_count”: 0,
“entities”: {
“hashtags”: [
{
“text”: “stelline16”,
“indices”: [
25,
36
]
},
{
“text”: “MLOLplus”,
“indices”: [
103,
112
]
}
],
“urls”: [
{
“url”: “https://t.co/pei5VQw8AI”,
“expanded_url”: “http://blog.mlol.it/2016/02/26/stelline-2016/”,
“display_url”: “blog.mlol.it/2016/02/26/ste…”,
“indices”: [
113,
136
]
}
],
“user_mentions”: [],
“symbols”: []
},
“favorited”: false,
“retweeted”: false,
“possibly_sensitive”: false,
“filter_level”: “low”,
“lang”: “it”,
“timestamp_ms”: “1458123117169”
}
Se siete curiosi di esplorare il network di tutti gli hashtag utilizzati durante il convegno, vi potete sbizzarrire con questo grafico dinamico, caricato su Github come gli altri linkati in questo post (non ho avuto tempo di scrivere le media queries, abbiate pazienza, guardateveli da un laptop per potere interagire). La grandezza dei nodi-hashtag è proporzionale alla quantità di occorrenze e quella dei nodi-user alla quantità di mention e retweet ricevuti legati a questo a quell’altro hashtag.
ma Veniamo al sodo
Concentrandomi sul grafo dei retweet, in assoluto l’elemento più importante per Twitter (l’attribuzione di autorità sociale per eccellenza, tanto che non a caso si parla di una vera e propria “semantica del RT“), ho estrapolato i 1007 retweet dal totale ottenendo un network di 186 nodi e 436 connessioni.
Non ho esplorato il mention network per vari motivi, principalmente però perché si tratta di un network conversazionale del tutto slegato, a quanto pare, dai meccanismi di “info spreading” che sono il vero motore di Twitter. In ogni caso esistono ancora troppe poche ricerche dove la conversazione su Twitter è analizzata senza una profonda analisi del contesto. Il che richiederebbe anche processi di text analysis e metodologie di approccio ben diverse (proprio a livello di design della ricerca). Esistono comunque varie scuole di pensiero. Se vi interessa ne parlavamo lo scorso settembre con alcuni gephi users qui.

Ho misurato il network con i parametri che mi interessavano di più:
- Betweenness centrality (chi sono i mediatori di informazione del network?)
- Eigenvector centrality (una naturale estensione delle degree centrality che si preoccupa di pesare i link in entrata per ogni nodo con un sistema di autorità e non solo di quantità. Per fare un esempio, se ricevo 10 retweet ma uno di questi è del presidente degli Stati Uniti, il valore per quel link in entrata dovrà essere pesato all’interno della mia rete e dovrà avere chiaramente un’importanza maggiore) e un modello molto interessante che ho scoperto qui, grazie a Andrea Mangiatordi.
- Il modello si chiama Twitter User Rank (TURank) ed è stato sviluppato da Yuto Yamaguchi, Tsubasa Takahashi, Toshiyuki Amagasa e Hiroyuki Kitagawa (Graduate School of Systems and Information Engineering e Center for Computational Sciences, University of Tsukuba) su tre principi:
- A user followed by many authoritative users is likely to be an authoritative user.
- A tweet retweeted by many authoritative users is likely to be a useful tweet.
- A user who posts many useful tweets is likely to be an authoritative user.
Il percorso più breve attraverso la rete (betweenness centrality, uno dei modelli su cui si basa anche la nostra cara internet).
Avevo fatto una prima misurazione della betweenness centrality giovedì notte sul tardi, a live tweeting fermo, per capire quali fossero gli account che in assoluto smistavano più connessioni all’interno del network.
Senza considerare la modularità, il ranking dei nodi della rete (ricordo, stiamo parlando solo di RT) per valore di betweenness centrality mi aveva restituito questo:

Poi, quando ho ricalcolato il tutto con i dati finali delle due giornate…


Cosa è successo? Molto semplice, nel pomeriggio di venerdì è entrato nel network Gino Roncaglia (fino ad allora presente con un solo RT fatto e nessuno ancora ricevuto).
Sono bastati 6 tweet di Gino Roncaglia per modificare radicalmente la struttura di #convegnostelline, consegnando alle metriche del grafo un punteggio di betwennes centrality di 1,489 (il quarto coefficiente più alto in assoluto) e segnalandolo come intermediario al pari di altri nodi consolidati che twittavano già da un giorno. Solo 6 tweet.
Tanto per ribadire che Twitter è in assoluto il real time network più sensibile all’autorità e all’influenza che si sia mai visto (network epidemiologici a parte).
Alcuni nodi sono più rilevanti di altri (eigenvector centrality e TuRank)
Quello che mi affascina, della eigenvector centrality, è principalmente il fatto che un nodo con un alto coefficiente di eigenvector non è sempre necessariamente connesso a molti altri nodi. E’ un ottimo sistema per considerare il livello di autorità di un attore del network. Può avere poche connessioni, ma importantissime. E’ sicuramente un aspetto di cui tenere conto nell’analisi, se non altro per non banalizzare la grandezza dei nodi con una semplice quantità di link in entrata.
Questo è il grafo definitivo con il ranking dei nodi calcolato sulla eigenvector centrality.

Sorprendentemente, applicando alla eigenvector il modello autoritativo TURank , il nostro network fa emergere alcuni nodi che nella rappresentazione ottenuta con la betweenness centrality erano passati in secondo piano. Questo è quello che succede quando si privilegiano metriche che caratterizzano la prominenza “globale” di un vertice (nodo) in un grafo, rispetto a quella “locale”.
Per fare un esempio, esattamente una delle funzioni principali che aveva il primo algoritmo di Google, Page Rank (ora lasciato morire senza più aggiornamenti dal 2014, ma per motivi molto lontani dalla semplice affidabilità o meno).
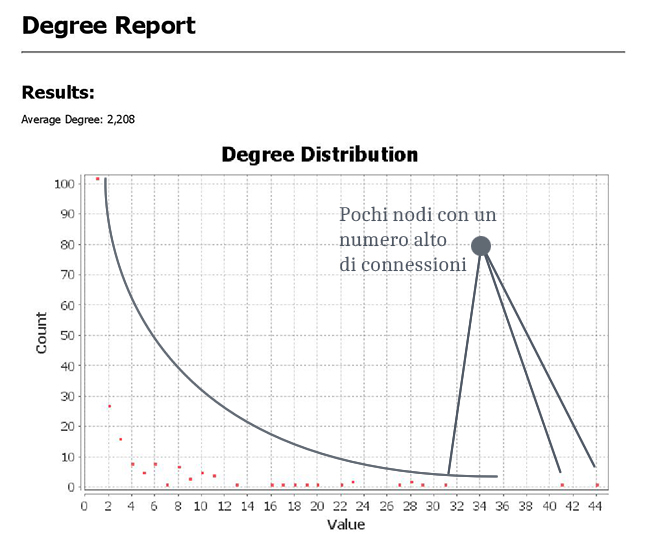
Power law?
L’ultima mia curiosità era se questo network, alla fine, si sarebbe potuto definire a invarianza di scala.
Cosa significa?
Vuol dire che, semplificando molto, mi chiedevo se sarebbe emersa una delle caratteristiche principali delle reti sottostanti alla legge di potenza, cioè la relativa frequenza di nodi con una degree altamente sopra la media.
Banalizzando ancora di più, volevo capire se sarebbero emersi nodi in qualità di veri e propri hub di comunità che, come succede appunto nei scale-free network, avrebbero dimostrato la resilienza della rete al fallimento.
Nella pratica, si cerca la rappresentazione di un asintoto verticale.
Solitamente questo tipo di reti, con una distribuzione dei gradi (degree) così eterogenea e che segue appunto una legge di potenza, è caratterizzata da pochi nodi con molte connessioni e molti nodi con poche. Molti social network hanno questa caratteristica, ma non tutte le sotto comunità al loro interno la ereditano automaticamente.
Nel caso si individui un network di questo tipo, si può dire che almeno tre delle sue caratteristiche sono:
- sei gradi di separazione
- poca connettività media generale
- robustezza
Prima di passare all’immagine, faccio solo notare che durante la corsa agli Oscar 2015, alcuni Studios hanno adottato un sistema di targeting pubblicitario diretto ai membri votanti della Academy e ai loro social network perché, come ha dichiarato Tobias Bauckhage (co-founder di Moviepilot):
We believe that the influence of the social network is actually more important than reaching the academy member directly
Lo hanno fatto, insomma, passando dagli hub e sfruttando tutti i meccanismi di info spreading possibili all’interno delle reti a invarianza di scala.
Poi capita magari di imbattersi anche in tweet come questo:
Infine, l’immagine. Che dite, ci siamo con l’asintoto?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Post come sempre “denso” ed interessante benché a tratti di non sempre facile comprensione per un “illetterato digitale” come il sottoscritto.
Sarebbe interessante, in prospettiva, ampliare e “storicizzare” l’analisi effettuata (a riguardo non so nemmeno se esistano strumenti adeguati…) per verificare se trovano conferma alcune mie impressioni ricavate osservando i grafici pubblicati, vale a dire: 1) gli influencer sono, salvo alcune new entry, sempre gli stessi delle edizioni precedenti 2) gli influencer twittano argomenti legati, grossolanamente, al “digitale in biblioteca” (e-book, digital lending, digital storytelling, etc); ciò che è poco o nulla digitale finisce, inevitabilmente, per restarne fuori 3) nonostante gli sforzi, un evento nazionale come quello delle Stelline non riesce ad insediarsi come Trending Topic a livello nazionale (ma, come fai giustamente notare, unificando l’hashtag si potrebbe fare di meglio!).
In altri termini non vorrei che anche Twitter sancisse quella che è la mia convinzione, ovvero che il “movimento” sviluppatosi e cresciuto circa 6-7 anni fa attorno alle novità (“rivoluzionarie” si diceva) portate dall’ebook, dal self publishing, etc., abbia perso buona parte del suo slancio e che, purtroppo, si sia caduti nell’autoreferenzialità e, di conseguenza, con scarsa capacità di comunicare all’esterno delle proprie reti consolidate.
"Mi piace"Piace a 1 persona
Simone, sulle edizioni precedenti purtroppo non posso e credo che non potrò mai dire nulla perché non ho dati (per saperlo bisognerebbe proprio comprarli dalla firehose di Twitter, l’unico modo per averli gratis è la cattura dello streaming in real time, con buona pace del 99% dei servizi che dicono di poterti fare l’analisi e che alla fine si limitano ai 200 tweet più recenti). Sul focus degli argomenti attenzione però, come ho scritto non ho minimamente affrontato text/sentiment analysis nè tantomeno link analysis (che forse sarebbe la cosa più interessante). Solo in quel caso potrei azzardarmi a dire: sí tutto bello ma la solita solfa. Io c’ero e ho sentito cose molto interessanti (altre banali, alcune banalissime), ma per l’uso in generale che è stato fatto di Twitter non è possibile valutare a posteriori alcuna completezza rispetto alla versione live (seguivo anche lo stream di #codemotion e notavo una differenza abissale, anche solo nelle critiche costruttive).
Il fatto comunque è che c’è un elefante enorme nella stanza, e penso l’abbiamo notato tutti, anche se non voglio accreditarmi l’osservazione che è stata fatta da qualcuno a cui spero presto di renderne il credito: l’assenza, tranne casi abbastanza ovvi (e virtuosi) come si evince dai grafici, dei vendor commerciali! E, se anche c’erano, non hanno magari sfruttato proprio benissimo il suo meccanismo (faccio ipotesi, non certo accuse). Ripeto, per parlare di auto-referenzialitá ci vorrebbe un lavoro a un altro livello, io mi sono limitato a evidenziare i nodi della rete secondo misurazioni ottenute da algoritmi sedimentati nella storia scientifica dell’ultimo secolo e passati di mano in mano ai più influenti fisici e matematici che se ne sono occupati (lo so, è OT rispetto alla tua domanda, ma sai il pericolo degli umanisti nche ignorano anche il solo semplice concetto di matrice è di bollare tutto come supercazzola, e questo, non nego, è anche colpa della divulgazione scientifica che ha un ritardo imperdonabile nel nostro paese).
Su una cosa hai assolutamente ragione: un solo hashtag avrebbe vinto qualcosa in più 😉
"Mi piace""Mi piace"
[…] a me stava portando avanti un lavoro eccellente di data mining e social analysis, i cui risultati ha esposto esaurientemente in un post dove spiega bene i numeri e quello che vogliono dire, traendo conclusioni data-based sulle […]
"Mi piace""Mi piace"